Better Source Code Navigation - Part 2: SourceGraph Literal Searches and Regex Searches


Introduction
Welcome back to part 2 of my SourceGraph tutorial. Today we will be looking at some practical examples of how to use regex and literal searches within SourceGraph to find interesting bits of code to help with various operations.
We'll start by doing a quick overview of SourceGraph's default search mode, the literal pattern search. This will be the most common type of search you will be performing so it will be good to review this as there are some quirks that you might not be used to if you are used to using a normal search engine.
Following this, we will take a look at how to enable regex-based searching within SourceGraph and will then examine some examples where I have used regex-based searching to solve some of my work problems. We will also try to use regex and literal searching to understand an unknown code base.
Understanding SourceGraph's Literal Search
By default, when you search in SourceGraph, you will be performing a literal search. Literal searches are most helpful when you know exactly what it is that you want to find within the code, as they are tailored towards narrowly focused searches. Most often you will want to use a literal search when you know a variable name, function name, or specific string from an error message or for some output that you want to find within the code.
One thing to note when doing literal searches though is that you will be doing quite literally a literal match on the string. So if you type default param, that is the string you will be searching for exactly. It will not search for the words default and param separately but will instead treat them as one search item.

If you wanted to instead search for results that match the word default or the word param you could use the boolean AND and OR keywords to find files that contain either both keywords (in the case of AND), or only one of the two keywords (in the case of OR).
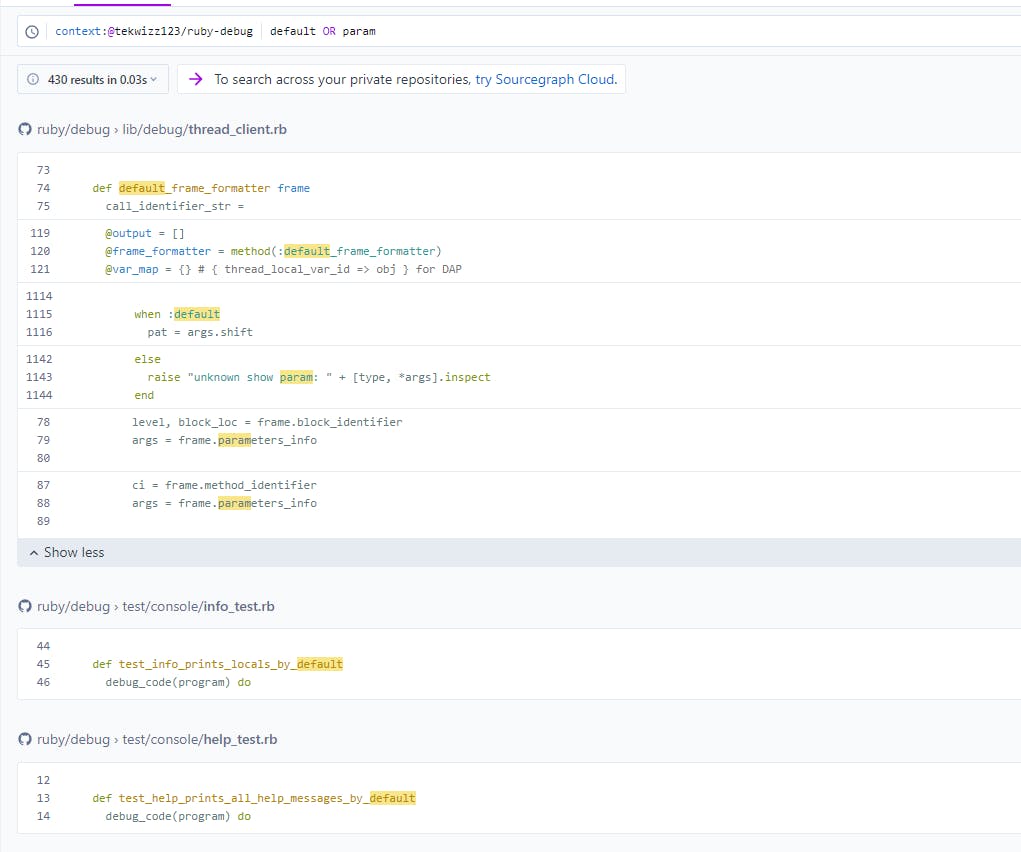
Note that if you attempt to put quotes into the search, those will be treated as literal quotes that will also be included in the items to search for. So "unknown show param: " would search for a line of code in the source code where that matches "unknown show param: " exactly, including the quotes, spaces, and casing.
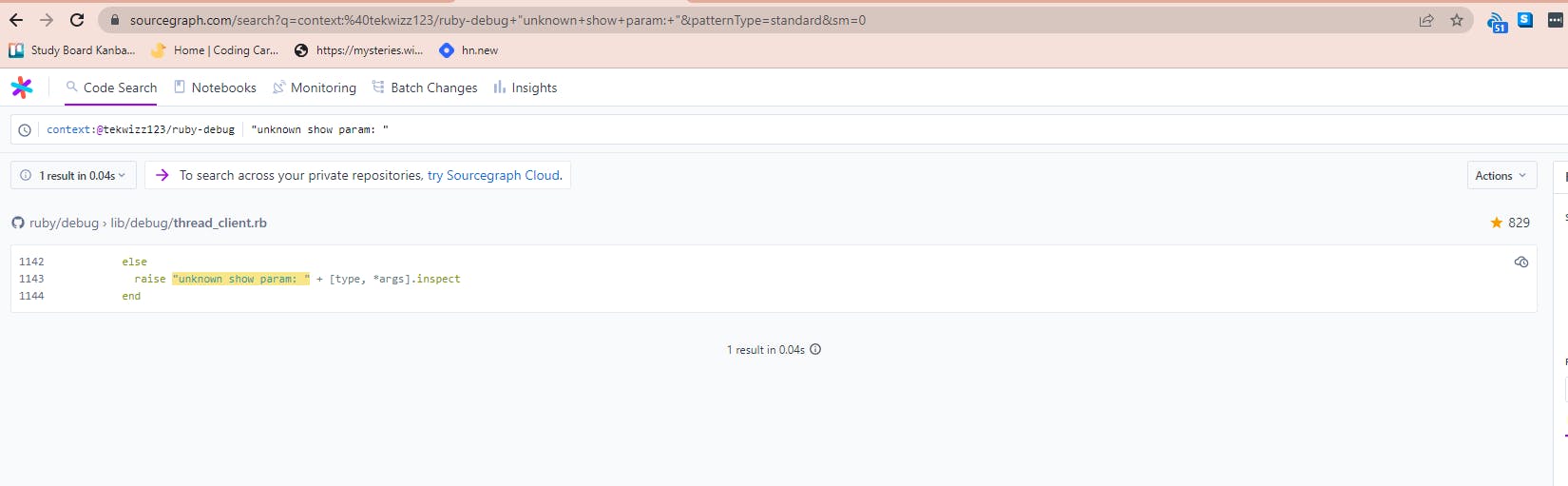
Changing Search Settings for More Results
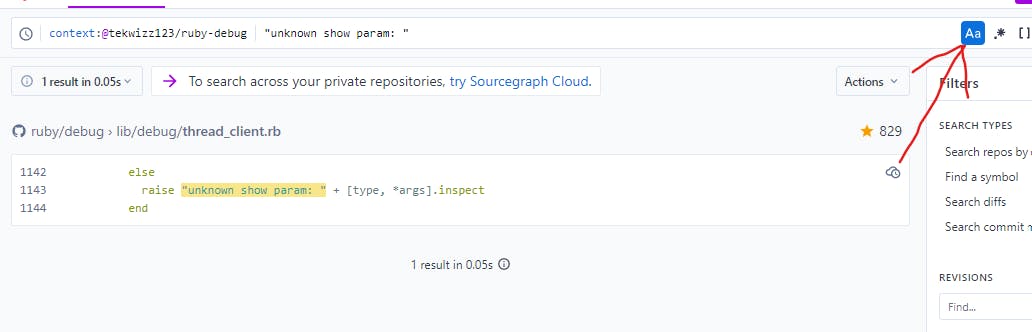
Note that if you want to make the search case insensitive you can go over to the icon on the right side of the search bar that looks like Aa and click on that. This will highlight it in blue and will indicate that you are performing a case-insensitive search:
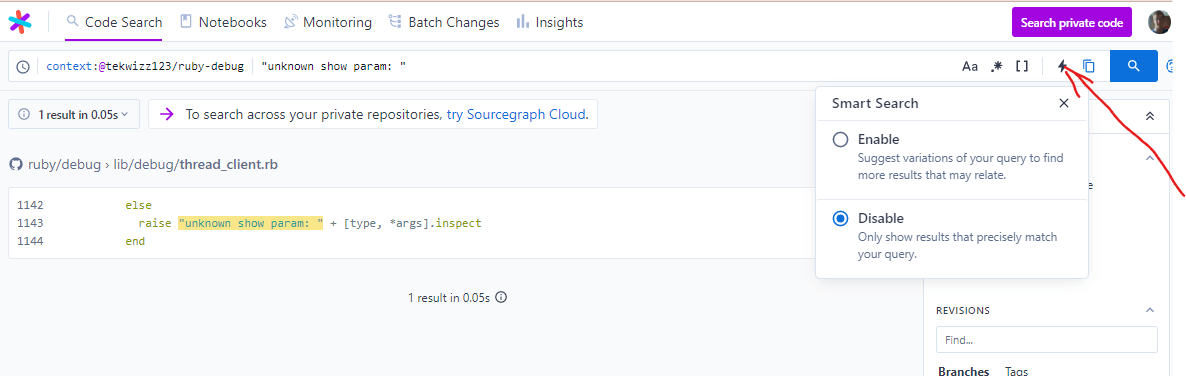
If you find that you are getting too few results, you can enable SourceGraph's Smart Search functionality by clicking on the lightning bolt on the right of the search bar. This will suggest variations on your query to find more results that may relate. The only downside of this I have found is that sometimes it will try to alter your search a bit to return more results by adding AND keywords if you do something like def param as a search, in which case it would treat it as a search for def AND param instead of just def param so keep this in mind.
Searching With Regex Within SourceGraph
To search with regex within SourceGraph, you first need to enable the regex search mode by clicking on the .* button to the right of the search bar:

Once this is done your search will turn into a regex search. Note that unlike in literal search mode, searching with quotes will now work as you would expect a normal search engine to work.
The picture above shows that a search for "unknown show param: " now matches the string unknown show param: exactly, but this time it doesn't include the quotation marks in the search results since these are not considered to be part of the match now.
If you wanted to instead match these quotes as well when searching in Regex mode, you will need to escape them using backslashes so your search would become \"unknown show param: \".
Note that SourceGraph uses the RE2 style of regex, the documentation for which can be found at https://github.com/google/re2/wiki/Syntax. This means that anything valid for RE2 regex will be valid in SourceGraph's regex searches. This is worth a read-through if you are looking for a guide to reference when formulating your regex syntax, and https://regex101.com/ can be used to help debug your regex when you are ready to start testing things out.
Common Regex when Searching With SourceGraph
Most commonly when searching with SourceGraph you will see the characters ^ and $ used. These stand for the line start and line end characters respectively and are used to match the beginning and end of a line. This is particularly helpful when you want to match lines that begin or end with certain characters whilst removing other matches that occur in the middle of the line.
Another particularly useful regex is the word boundary, aka \b, which can be used to denote the beginning or end of a word. For example, searching for \bcount\b will ensure that you have a word boundary before and after the word count, which will ensure you don't match results such as countName or names_count or similar.
An important point to note is that in regex mode, a space between two keywords will match any characters that occur between those two keywords on the same line. There is a good example of this at https://sourcegraph.com/search?q=auth%20service%20patternType%3Aregexp&utm_source=learn if you wish to see an example.
Finally, one can search using character classes and repetition counts. To create a character class, use [<characters here>] to create a new character class. You can use shortcuts in some languages, such as [\w] to specify all word characters. To do a nonmatching character class, use the syntax [^<characters here>] to create a list of characters you don't want to match. You can then specify how many times you want this to repeat with the {<count number here>} syntax to match exactly the specified number of repetitions, {x, m} to match between X and M times inclusive, or {x, } to match X or more times preferring more matches.
If you want to learn more about regex I highly recommend reading the tutorials over at https://regexone.com/. They have a great set of lessons that greatly helped speed up the learning process.
Practical Examples
Now that we have gone over some of the common regex patterns and taken a look at both literal and regex based searches in SourceGraph, let's take a look at some practical examples of how I have used these types of searches in my work with Metasploit.
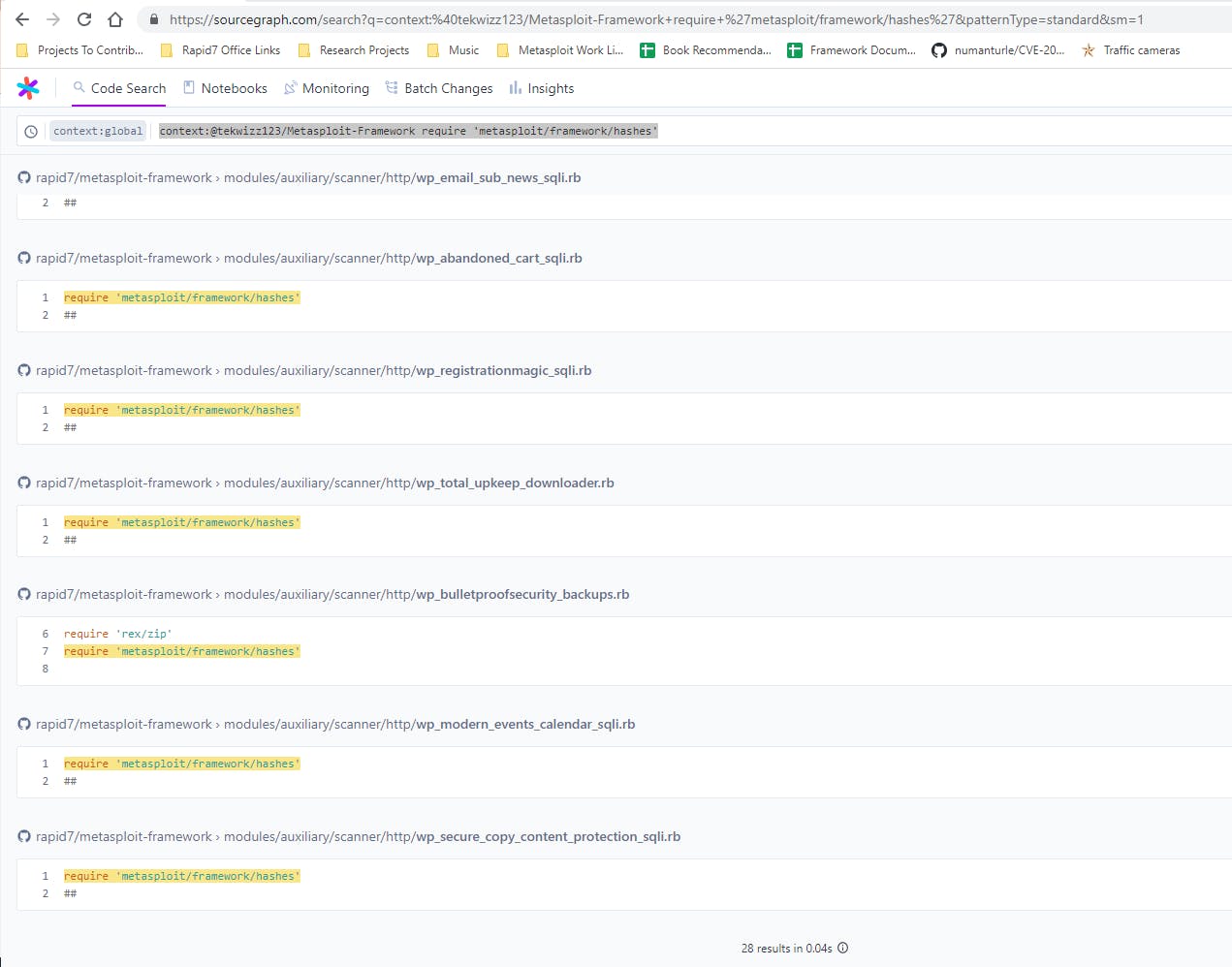
In one case I was curious to know where the metasploit/framework/hashes library was being used. This library is often used to identify hash types from a string before saving them into the database. I knew from the existing file that this is typically included using the command require 'metasploit/framework/hashes' so I created a search query using the global context with the search string context:@tekwizz123/Metasploit-Framework require 'metasploit/framework/hashes'.
This search uses the @tekwizz123/Metasploit-Framework context, which just does repo:^github\.com/rapid7/metasploit-framework$ to ensure that we are just searching the Metasploit Framework repository. You can read more about search contexts in my previous article at https://tekwizz123.hashnode.dev/better-source-code-navigation-part-1.
Searching for this shows 28 files that use this line to import the hashes library, so I can get a good idea of what modules are using this code and might be affected by changes to it:
Another example that I recently had to do was that we noticed that the RailGun API wasn't updated to support 64-bit payloads in some circumstances, which was leading to sessions crashing because 64-bit long pointer addresses were being truncated to 32-bit long pointer addresses, leading to access to invalid memory.
What I realized was a lot of this was related to our use of PDWORD in our definition files to declare the return value as a pointer to a DWORD, when in some cases this was not the correct return type to use. I started my search by searching for all files containing the word PDWORD which were also Ruby files by using the search context:global repo:^github\.com/rapid7/metasploit-framework$ PDWORD lang:ruby.
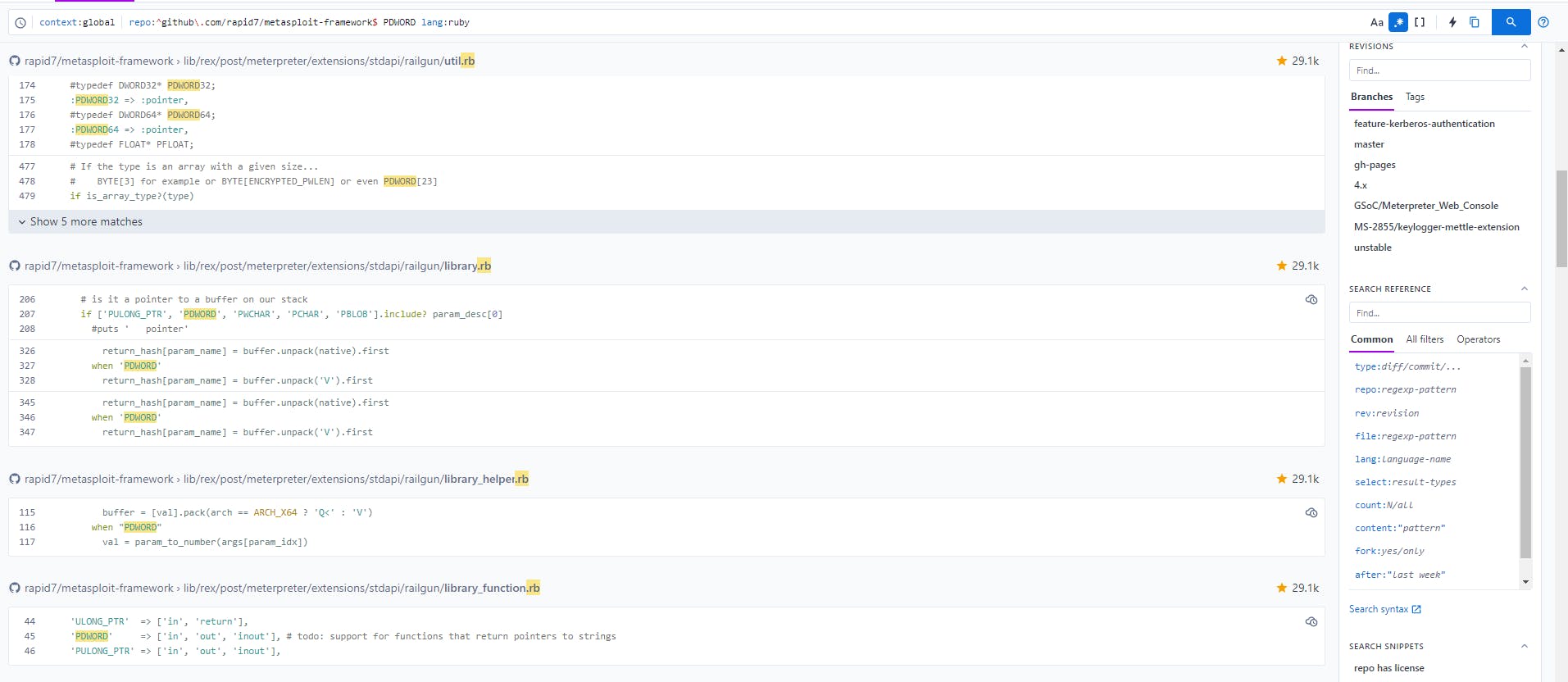
Looking through these results we see a few definition files however the one that caught my eye was lib/rex/post/meterpreter/extensions/stdapi/railgun/library.rb, and specifically its mention of native when performing a Ruby unpack() operation. I quickly looked up the notation for unpack() at https://apidock.com/ruby/String/unpack and noticed the V syntax being used was for a 32-bit unsigned value in little-endian byte order, as shown at https://sourcegraph.com/github.com/rapid7/metasploit-framework/-/blob/lib/rex/post/meterpreter/extensions/stdapi/railgun/library.rb?L328 for out only buffers.
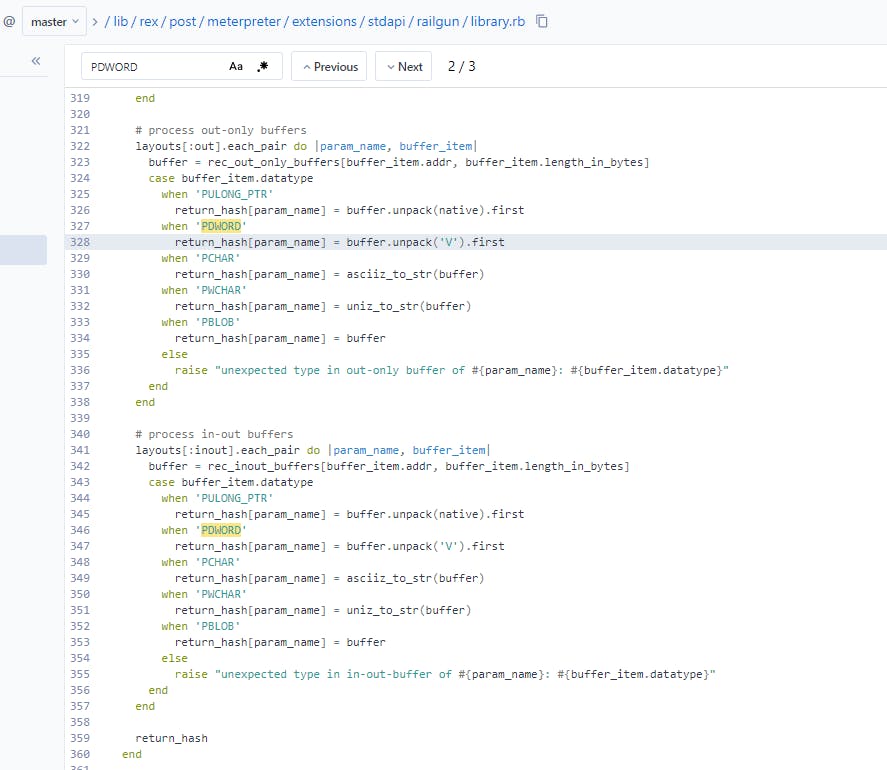
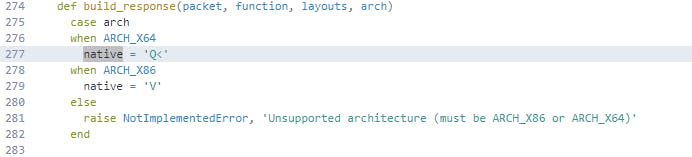
Interestingly though, we can also see that there is an unpack operation which uses the variable native when specifying a PULONG_PTR type. If we hover over this in SourceGraph we can see it is defined as Q<:
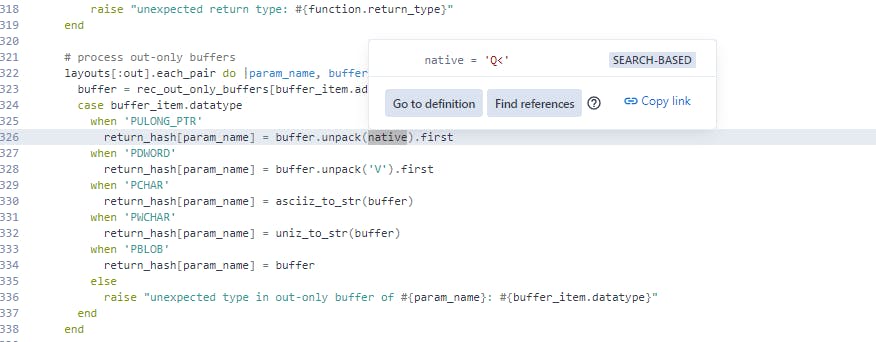
Clicking Go to definition shows us something interesting. Within the build_response function we have a check that will set native to Q< if the platform architecture is ARCH_X64, aka the target is a 64-bit platform, or V if it is ARCH_X86, aka a 32-bit platform. This matches our initial observation that the numbers were being truncated.
Going back to our original search of context:global repo:^github\.com/rapid7/metasploit-framework$ PDWORD lang:ruby and scrolling down a bit more, we can see a lot of definition files under the path lib/rex/post/meterpreter/extensions/stdapi/railgun/def/windows/ that define functions for various calls with the syntax ["<return type>", "<function name>", "<direction>"] where the return type might be something like PDWORD, the function name is the name of the function, and the direction is the direction of the buffer such as in for an input-only buffer, out for an output-only buffer, or inout for a buffer that both sends input and receives output.
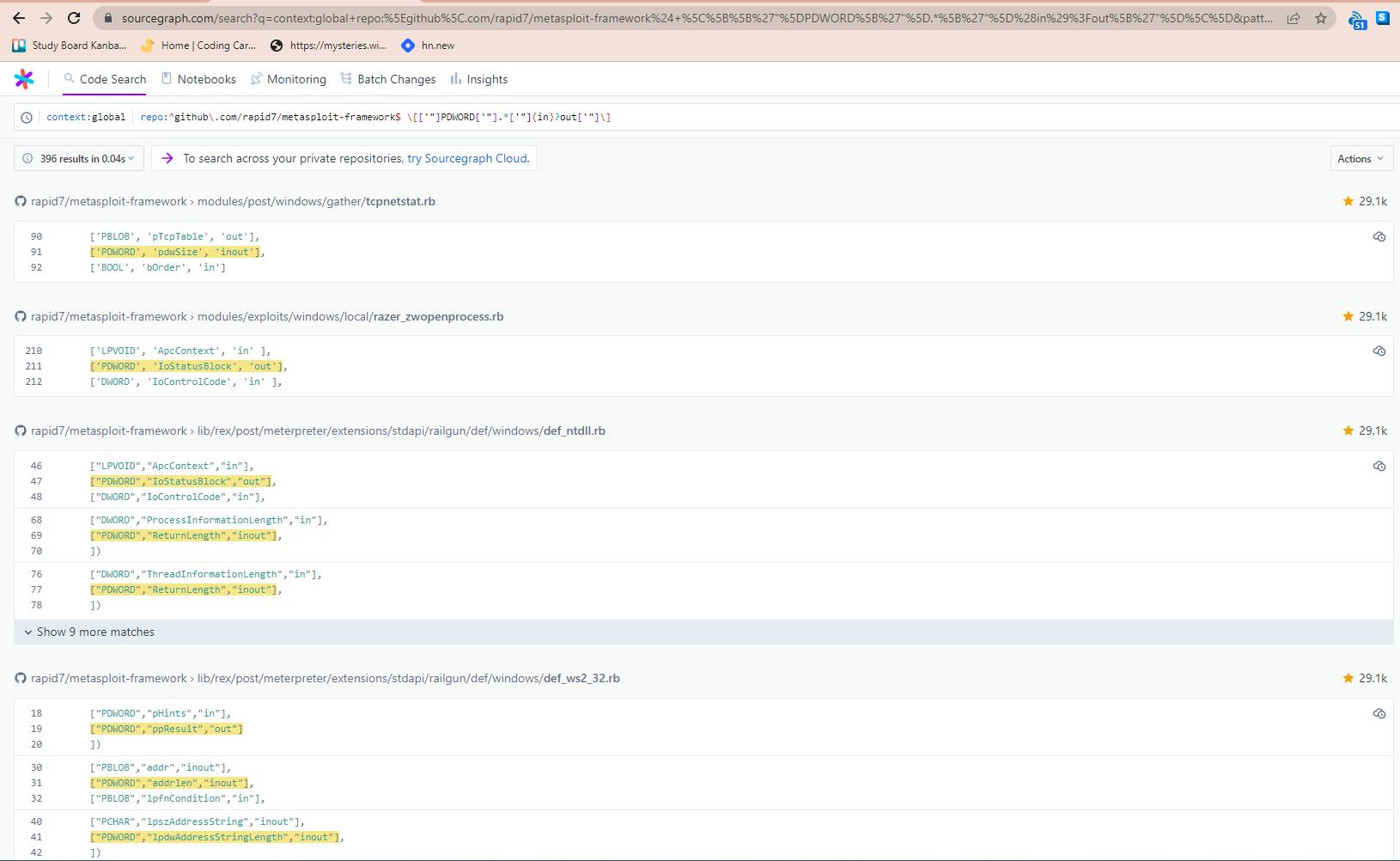
I was interested in only those fields defined as being a PDWORD type though so I wrote a regex query to filter these out, ignoring both the function name and direction, with the query \[['"]PDWORD['"].*['"](in)?out['"]\] which will search for anything starting with a [ and ending in ] that also contains the keyword PDWORD wrapped in either single or double quotes, followed by any series of characters, and then the word out or inout in single or double quotes to denote that buffer is also an output buffer.
From this, we get 396 results which are spread across 13 files, which we can now work through to verify and update the calls as needs be to be compatible with x64 sessions:
Conclusion
With some knowledge of how to do regex searches as literal searches in SourceGraph, as well as how to toggle the case sensitivity and Smart Search settings, you should be able to use SourceGraph to solve a wide variety of common scenarios within your everyday workflow that require the ability to locate certain functionality within one or more codebases.
The next tutorial will focus on one final feature of SourceGraph that I'd like to showcase, namely the Structural Search option. This one is a little bit more complex, so we'll dive into this deeper in the next tutorial and explore some more of the intricacies surrounding this search type, which is fairly unique to SourceGraph.